youtube-parser
yt-parser is a versatile YouTube video parser designed to streamline the extraction of transcripts from individual videos, playlists, or entire channels. By simply inputting a YouTube video URL, playlist URL, or channel URL, users can initiate the process, which automatically generates English transcripts for each video regardless of its original language. These transcripts are then efficiently segmented and transmitted as JSON responses to both Minio and webhooks for seamless integration with downstream applications. Leveraging this parsed content, the system empowers Bharat Sahai Yak to orchestrate a sophisticated chatbot experience based on the extracted insights, facilitating dynamic interactions and informed responses.
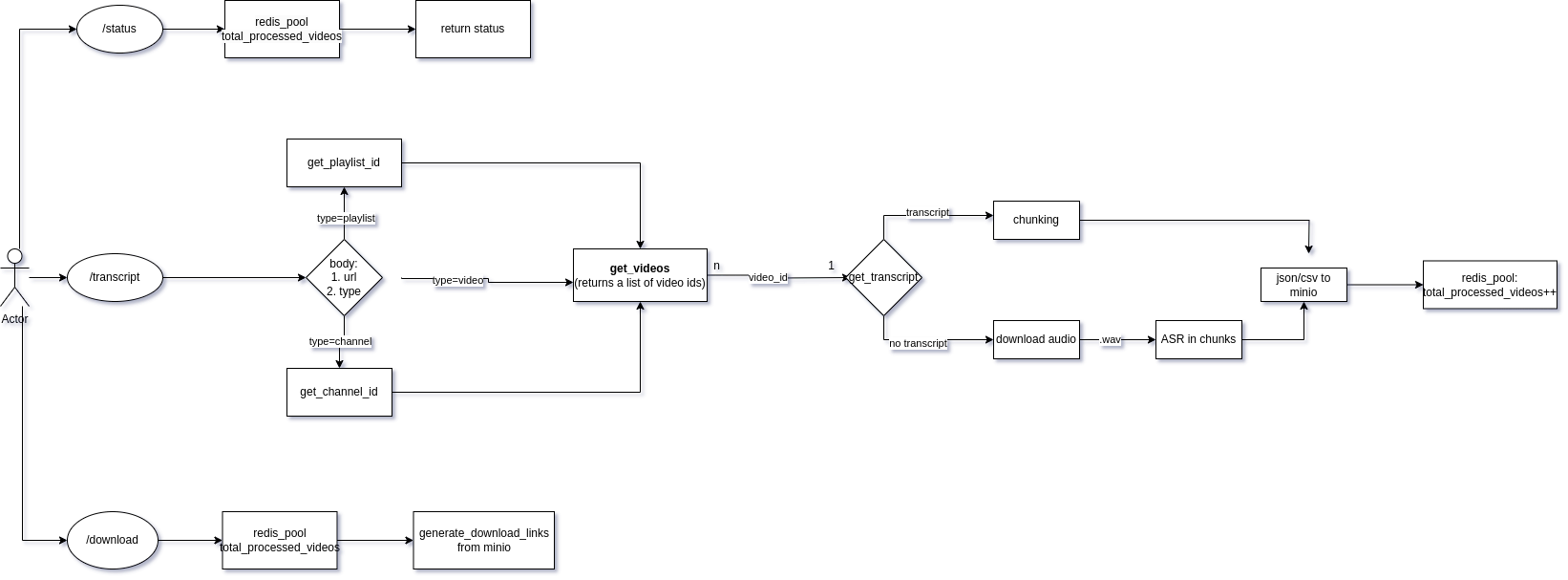
Working and architecture
User Input: User submits a URL and URL type to the system.
Generate Video IDs: Video IDs are generated for all videos in the playlist, channel, or for a single video.
Retrieve Transcripts: Video IDs are used to retrieve the YouTube-generated transcripts from the YouTube Data API.
Chunk Transcripts (if needed): Transcripts are chunked into segments of 4 minutes.
Translate Non-English Transcripts: Non-English transcripts are translated to English if available.
Send Transcript Chunks via Webhook: Each transcript chunk is sent via webhook to the designated receiver in a predefined format.
Store Transcript Chunks to Minio: Transcript chunks are saved to Minio in both JSON and CSV formats.
Invoke ASR Way (if English transcript unavailable):
- Download and Split Video Audio: Video audio is downloaded and split into 4-minute chunks.
- Process Audio using ASR: Each audio chunk is processed using ASR services.
- Send ASR Results via Webhook: ASR results are sent via webhook to the receiver.
Architecture Diagram:
Setup - Docker Way
To set up yt-parser using Docker, follow these steps:
Install Docker: Ensure Docker is installed on your system. You can download and install Docker from here.
Build Docker Image:
docker build -t yt-parser:latestRun Docker Compose:
docker-compose up -dyt-parser should now be running and accessible at http://localhost:8000
Setup - Manual Way
For manual setup, follow these instructions:
- Install Dependencies: Ensure you have Python 3.10 installed on your system. Additionally, install
ffmpeg:sudo apt-get update
sudo apt-get install ffmpeg
2. Manual Setup Way
For manual setup, follow these instructions:
Install Dependencies: Ensure you have Python 3.10 installed on your system. Additionally, install
ffmpeg:sudo apt-get update
sudo apt-get install ffmpegCreate and activate virtual enviroment
python3 -m venv venv
source venv/bin/activateInstall Python Dependencies: Install Python dependencies using Poetry:
poetry installSet Environment Variables: Create a
.envfile based on the sample environment file provided (sample.env). You can find the sample environment file in the repository here.Example:
cp sample.env .envStart Redis Server: Start the Redis server. You can use Docker or install Redis locally.
Run yt-parser: Start the yt-parser application:
uvicorn main:app --host 0.0.0.0 --port 8000Run Celery Worker: Start the Celery worker:
celery -A worker worker --loglevel=infoAccess yt-parser: yt-parser should now be running and accessible at
http://localhost:8000.
API Endpoints
1. /download
Query Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| taskId | String | YES | The task ID. |
Curl Request
curl http://localhost:8000/download?taskId=<TASK_ID_HERE>
Response Format
- Success
{
"error": false,
"data": {
"batchId": "<BATCH_ID_HERE>",
"taskId": "<TASK_ID_HERE>",
"url": "<URL_HERE>",
"files": {
"<TASK_ID_HERE>": [
{
"start": "0",
"end": "50",
"url": {
"md": "<URL_MD_HERE>"
}
}
]
}
}
}
- Failure:
{
"error": true,
"message": "Error message",
}
2. /process
Request Body
| Name | Type | Required | Description |
|---|---|---|---|
| url | String | YES | The YouTube URL (video, playlist, or channel). |
| type | String | YES | The type of URL (valid types: "video", "playlist", "channel"). |
| webhookUrl | String | NO | The webhook URL to receive notifications (overrides environment variable). |
| language | String | NO | The language of the video in which transcription will happen. |
Curl Request
curl -X POST -H "Content-Type: application/json" -d '{"url": "<URL_HERE>", "type": "<TYPE_HERE>"}' http://localhost:8000/process
Response Format
- Success:
{
"error": false,
"message": "Task initiated successfully",
"data": {
"batchId": "batch_id",
"taskId": ["task_id_1", "task_id_2", ...]
}
} - Failure:
{
"error": true,
"message": "Error message",
"data": {}
}
3. /status
Query Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| taskId | String | NO | The task ID. |
| batchId | String | NO | The batch ID. |
Curl Request
# If you have taskId
curl http://localhost:8000/status?taskId=<TASK_ID_HERE>
# If you have batchId
curl http://localhost:8000/status?batchId=<BATCH_ID_HERE>
# If you have both taskId and batchId
curl http://localhost:8000/status?taskId=<TASK_ID_HERE>&batchId=<BATCH_ID_HERE>
Response Format
taskId and batchId provided:
{
"error": false,
"message": "Transcription is in progress.",
"data": {
"batchId": "<batch_id>",
"taskId": "<task_id>",
"taskStatus": {
"percent": 50,
"total": 10,
"stage": ""
},
"batchStatus": {
"percent": 20,
"total": 5
}
}
}batchId provided
{
"error": false,
"message": "Transcription is in progress.",
"data": {
"batchId": "<batch_id>",
"batchStatus": {
"percent": 20,
"total": 5
}
}
}
- taskId provided
{
"error": false,
"message": "Transcription is in progress.",
"data": {
"batchId": "<batch_id>",
"taskId": "<task_id>",
"taskStatus": {
"percent": 50,
"total": 10,
"stage": ""
}
}
}
- Failure:
{
"error": true,
"message": "Error message",
}
WEBHOOK Format
Webhook is been triggered in following events:
- A successfull chunk is created (either through API or explicit transcription).
- An error occurs after taskId is generated.
Webhook Response format:
Success:
{
"error":False,
"data":{
"batchId":batch_id,
"taskId":task_id,
"url": <video url>,
"chunks":[
{
"content": {
"heading":'',
"text":"Hey this is the transcript"
}
}
],
"metadata":{
"start":0,
"end":240
},
"taskStatus": {"percent":100,"stage":"Transcribing","total":4},
"batchStatus": {"percent":66,"total":36}
}
"message":""
}Failures:
{
"error":True,
"data":{
"batchId":batch_id,
"taskId":task_id,
"url": <video url>,
"chunks":[],
"metadata":{},
"taskStatus": {"percent":100,"stage":"Transcribing","total":4},
"batchStatus": {"percent":66,"total":36}
}
"message":"Error: "
}