Generation
Nipun SahAIyak is a platform to augment education with AI. More info about Nipun SahAIyak here.
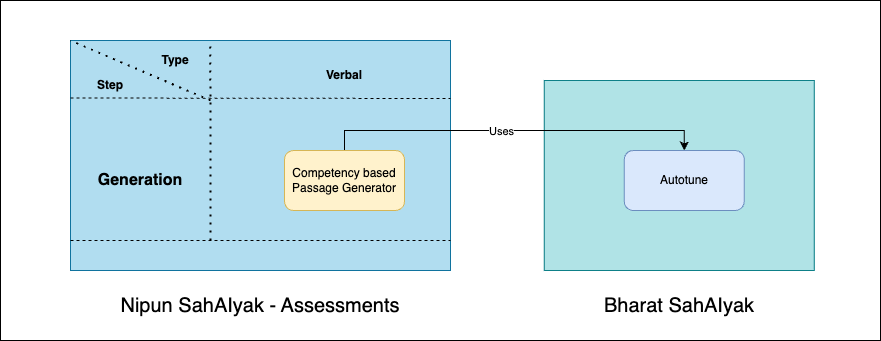
Generation is the step of Bharat SahAIyak's AI augmentation for assessment flows where content of the assessments is generated using AI.
Verbal Assessments
A typical verbal assessment flow consists of a paragraph that the assessee is supposed to read at a particular correctness and speed for evaluation. The complexity of these passages changes with grade levels and the assessment thresholds change too. We can use AI to generate these passages in different languages.
For this Nipun SahAIyak contains the Compentency based Passage Generator. This generator uses Autotune's Dataset Builder from Bharat SahAIyak to create the best prompt and model combinations to generate the required passages.
The user is required to enter the complexity of the passage into the prompt along with the model of the users choice to start a workflow. Dataset Builder generates the results and displays it to the user. The user can then mark the output as good examples or bad examples. The good and back examples are appended to the previous prompt leading to better results in subsequent runs till the user is happy with the generated results. The generated prompt and examples are save as a part of workflow which can be used later for fine tuning and ingestion of questions. More info about Dataset Builder {here}
Non - Verbal Assessments
A typical non - verbal assessment flow consists of a form containing questions and the assessee entering or selecting the correct answer. The questions can be:
- Comprehension based questions - Where a comprehension is shown to the assessee and related questions are asked.
- Multiple choice questions - Where a question and some choices are shown to the assessee where one of the choices is correct.
- Free text questions - Where a question is shown to the assessee and the answer is expected as a short paragraph or a long paragraph.
Nipun SahAIyak augments the generation of all the above question types with AI with the Competency based Q&A Generator. This generator also internally uses Autotune's Dataset Builder to allow the user to tune their prompts with good and bad examples.
API
Request Body
{
"workflow_name": "Grade 1 - Math Competency Questions",
"competency_id": "b5b2a68a-3ddd-462c-a79a-382a3b1ea3be",
"prompt_schema_format": "QnA",
"tags": [
"string"
],
"user_prompt": "The task is to generate questions to test addition and substraction for grade 1 students. Your task is to generate addition questions or subtraction questions with single digits numbers."
}
Definition:
| Name | Type | Required | Description |
|---|---|---|---|
| workflow_name | string | Yes | The name of the workflow for the task. |
| competency_id | string | Yes | The unique identifier for the competency being tested. |
| prompt_schema_format | string | Yes | The format for the prompt schema. By default there are few templates present to help generate examples compatible with the GAP format. For now comprehension and QnA values are allowed. |
| tags | array | Yes | A list of tags categorizing the type of content |
| user_prompt | string | Yes | Prompts to be passed to LLM model to generate the questions |
Request Body
{
"total_examples": 6,
"max_iterations": 5,
"batch_size": 3,
"user_prompt": "string",
"examples": [
{
"text": {... example object},
"label": "",
"reason": ""
}
],
}
Definition:
| Name | Type | Required | Description |
|---|---|---|---|
| total_examples | number | Yes | The total number of examples to generate for the task. |
| max_iterations | number | Yes | The maximum number of iterations allowed for generating the examples. |
| batch_size | number | Yes | The number of examples to be processed in each batch. |
| user_prompt | string | Yes | Users can use this field to fine tune the prompt in each iteration |
| examples | array | Yes | A list of examples to guide the generation process. Ideal example list should contains specific cases or scenarios to be included. |
| examples.text | any | Yes | AI generated data in the format specified while creating the workflow |
| examples.label | any | Yes | Tags categorizing the type of content |
| examples.reason | string | Yes | Explanation to specify why an example is correct or incorrect that helps fine tune the responses generated by LLM |
Response
{
"workflow_cost": "$0.0110",
"iteration_cost": "$0.0019",
"estimated_dataset_cost": "$0.0095",
"data": []
}
Definition:
| Name | Type | Required | Description |
|---|---|---|---|
| workflow_cost | string | Yes | The total cost incurred for running the workflow |
| iteration_cost | string | Yes | The cost incurred for each iteration |
| estimated_dataset_cost | string | Yes | The estimated cost for generating the dataset |
| data | array | Yes | A list containing the generated data that can be used again in the iteration step |
Request Body
{
"total_examples": 10,
"batch_size": 10
}
Definition:
| Name | Type | Required | Description |
|---|---|---|---|
| total_examples | number | Yes | Total number of examples to generate |
| batch_size | number | Yes | The number of examples to be processed in each batch. |
Response Body
{
"message": "Tasks creation initiated",
"task_id": "813ae503-bbce-4da7-a1e7-2babb218f543",
"workflow_id": "0d472090-3cf7-4c5f-8a1f-6c1d0ad13494",
"expeced_cost": "0.0095"
}
Definition:
| Name | Type | Description |
|---|---|---|
| message | String | Describes the status or action taken |
| task_id | String | Unique identifier for the task |
| workflow_id | String | Unique identifier for the workflow |
| expeced_cost | String | Expected cost of the task execution |
Definition
| Name | Type | Required | Description |
|---|---|---|---|
| workflow_id | uuid | YES | Unique identifier for the workflow |
| task_id | uuid | YES | Unique identifier for the task |
| page | number | NO | The current page number in a paginated list. It indicates which page of results is being requested or displayed. If not specified, all data will be sent. |
| page_size | number | NO | The number of items per page in a paginated list. It defines how many results should be displayed on each page. If not specified, all data will be sent. |
Response Body
[
{
"example_id": "b556ef80-7eb2-4e8e-8cbe-d774cb7119c8",
"prompt_id": "0096138f-4c70-43c8-aee2-466f354e21cc",
"text": "5 + 3",
"choices": [
{
"text": "7",
"score": 1
},
{
"text": "8",
"score": 0
},
{
"text": "6",
"score": 0
},
{
"text": "5",
"score": 0
}
]
},
{
"example_id": "cfaf2c88-c4a0-42be-bd92-da7e50666faf",
"prompt_id": "0096138f-4c70-43c8-aee2-466f354e21cc",
"text": "9 - 5",
"choices": [
{
"text": "4",
"score": 1
},
{
"text": "2",
"score": 0
},
{
"text": "3",
"score": 0
},
{
"text": "7",
"score": 0
}
]
}
]
Definition:
| Name | Type | Description |
|---|---|---|
| example_id | String | Unique ID associated with the generated example |
| prompt_id | String | Prompt identifier used to generate this example |
| ...text | any | Generated dataset based on the prompt schema format |
Request Body
{
"workflow_id": "0d472090-3cf7-4c5f-8a1f-6c1d0ad13494",
"task_id": "813ae503-bbce-4da7-a1e7-2babb218f543",
"example_ids": ["cfaf2c88-c4a0-42be-bd92-da7e50666faf", "b556ef80-7eb2-4e8e-8cbe-d774cb7119c8"],
"question_type": "single-select",
"competency_id": "b5b2a68a-3ddd-462c-a79a-382a3b1ea3be",
"prompt_schema_format": "QnA",
"config": {
"text": "Attempt the questions on a copy and answer them below.",
"group_size": 4
}
}
Definition
| Name | Type | Required | Description |
|---|---|---|---|
| workflow_id | String | Yes | Unique identifier for the workflow |
| task_id | String | Yes | Unique identifier for the task |
| example_ids | Array | Yes | List of example identifiers |
| question_type | String | Yes | Type of question, e.g., "single-select" |
| competency_id | String | Yes | Unique identifier for the competency |
| prompt_schema_format | String | Yes | Format of the prompt schema, e.g., "QnA" |
| config | Object | Yes | Configuration object containing additional details |
| config.text | String | Yes | Additional instructional text to be added in the questionnaires |
| config.group_size | number | Yes | Size of a group for the QnA type datasets |
Response
{
"id": "90IcAqHNbAv0",
"competency_id": "b5b2a68a-3ddd-462c-a79a-382a3b1ea3be",
"data": {...ingested questionnaires},
"description": null,
"created_at": "2024-05-17T05:16:56.187Z",
"updated_at": "2024-05-17T05:16:56.187Z",
"is_active": true
}
Definition
| Name | Type | Required | Description |
|---|---|---|---|
| id | String | Yes | Unique identifier for the object. |
| competency_id | String | Yes | Identifier linking to a specific competency. |
| data | Object | Yes | List of ingested questionnaires |
| description | String | No | Optional description of the object; may be null. |
| created_at | String | Yes | Timestamp of object creation. |
| updated_at | String | Yes | Timestamp of last update. |
| is_active | Boolean | Yes | Indicates whether the object is currently active. |